
Last Friday we sent out our first email to our list, and we got a tremendous response. Our open rate was 55% and our click-through rate was 24%. Frankly, that’s borderline unbelievable. For comparison, average open rates are around 20% and average click rates are around 3%. So we feel great about the response. We have two plausible explanations for the success, and it’s most likely a combination of both: 1) we used a super simple email template that only had one purpose–to get a click, and 2) this was the first email that we sent to our list, creating natural curiosity. We’ll see how our open and click rates hold up.
One tool that we used with our email, and will continue to use, was an A/B test.
An A/B test is where two different options are tried in order to find out which performs better. While this may seem like an obvious good idea, in practice many organizations fail to bother to set up A/B testing. The practice is very much grounded in the modern tenets of “Lean-startup” and “Fast-prototype”. The ideas is that we don’t know which will perform better. Do people like the large colorful click button? Or does that distract from the page? Do people respond to sentence X better or sentence Y? The ability to acknowledge that we don’t know and to run a test is crucial to making things better over time.
So on to the test. We did a simple A/B split on our email by trying two different subject lines, and one performed better, although it ended up being close. The first subject line that we tested (A) was “Visit the new getbrode.com”. The second subject line that we tested (B) was “GetBrode.com has launched – check it out”. The subject A was an action, B was a news item. We took two random samples of 96 email addresses and tested to see which one got better response.
MailChimp is our email service provider, and they do all the hard work for us.
Here are the results:
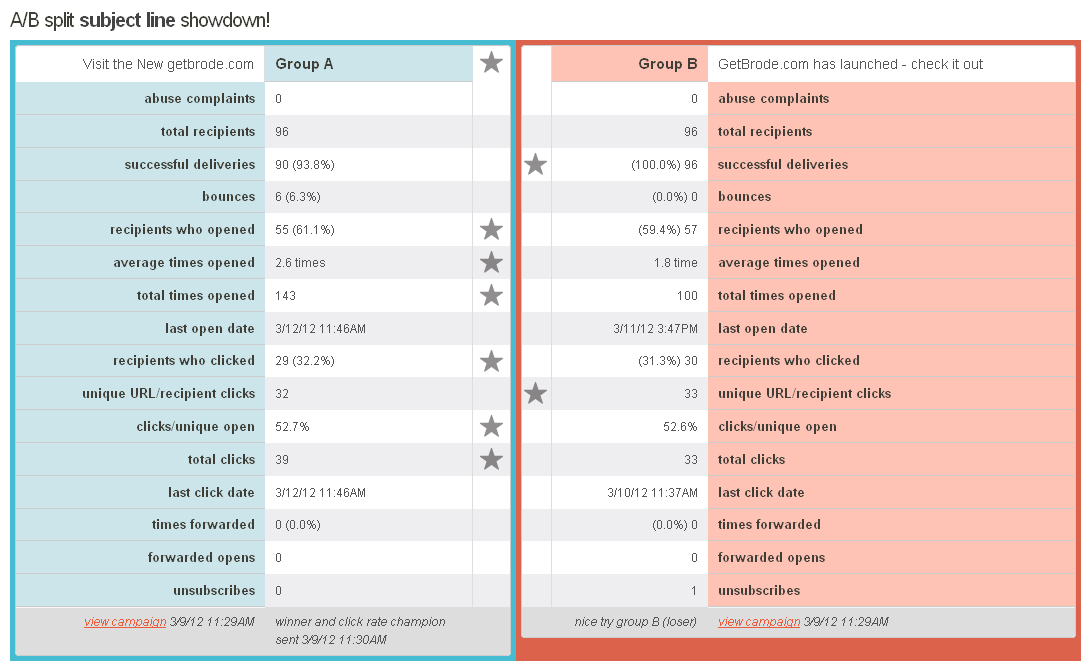
As you can see, subject A (with the action) performed marginally better than B with regard to opens and clicks. An hour after the test email went out, the remainder of the emails were sent to the full list using subject line A.
Now for something more interesting. Given the A/B test results, what are the chances that A is actually performing better, and not just showing a better result due to “statistical noise”?
Basic statistics, that most confusing of math disciplines, can shed some light. Anyone remember the chi-squared test? The ChiSq test asks – what is the likelihood that these two samples come from the same population, given their difference? Basically, what’s the chance that they are really the same?
If you run a Fisher Exact test on the data, you get a P-value of 0.88. What does this mean? It means that the probability that you get these results from randomness alone is 88%. The chances that this result can be explained by random variation along are quite high–so the results are not conclusive at all. A P-value below 0.05 is considered fair, and a P-value below 0.01 is often considered conclusive (but every test should have different standards).
What this means for our email test is that our two options, A and B, did not perform differently enough in the sample to be significant–we didn’t learn anything. Both performed great, though. In the future, we may want to try subject lines that are more different from each other so that we can get a better test result.
Looking to learn a bit more about online statistical testing? Here’s a treat.
Marc Brodeur just wants everyone to be awesome. His first company, Brode, the first professional drinking companion, makes a special vitamin that helps promote proper hydration and detox when drinking alcohol. Follow him on Twitter and Tumblr.



